Web scraping or Web harvesting is a data collecting technique by which users (manually) or computer software extract data from Web pages. Besides collecting the information, the process also usually transforms the data so it can be stored as tabular data or mapped to a schema to help further analyze the data.
Web scraping does raise legal questions. Basically, scraping only publicly available data is OK, but bypassing a website's security or authentication to gather extra information is a legally (in some countries) and ethically unacceptable way of collecting data. So, please keep this in mind when you are writing a Web scraper tool.
Web scraping, Web crawling, website indexing, and website semantic analysis are all related, and are based on analysis and categorization of Web page content. In this article I will demonstrate how you can use Scrapy, an open source Web scraping framework, for mining data on the Web.
Installing Scrapy is easy. For Ubuntu-based linux distros you can find the installation steps here and the installation for other platforms is detailed in the installation guide.
After installation, you can bootstrap a new Scrapy project using the command:
$> scrapy startproject wsfreelancerThis command will create a new folder called wsfreelancer with the following structure:
.
├── scrapy.cfg
└── wsfreelancer
├── __init__.py
├── __init__.pyc
├── items.py
├── items.pyc
├── pipelines.py
├── settings.py
├── settings.pyc
└── spiders
├── freelancer.py
├── freelancer.pyc
├── __init__.py
└── __init__.pyc
2 directories, 12 filesScrapy has two basic concepts. There's items, which are data holders and objects, that hold the data extracted from the Web page. The second concept is spiders, which are Python classes that contain the details on how to parse and transform the data on the Web pages.
I called the project wsfreelancer, because I am Web scraping the Freelancer.com website. You can create custom spiders the same way, but every spider has to derive from the Spider base class from Scrapy.
You can auto-create Web spiders using this command:
$> scrapy genspider [SPIDER NAME] [DOMAIN]
$> scrapy genspider wsfreelancer freelancer.comThe items.py file only has one class, but you can add more:
import scrapy
class WsfreelancerItem(scrapy.Item):
project_name = scrapy.Field()
nr_of_bids = scrapy.Field()
description = scrapy.Field()
skills = scrapy.Field()
price = scrapy.Field()The scrapy.Field() creates a new object that holds parts of the data from the webpage (the creation of Scrapy items is similar to how you create models in Django). The Field object is a wrapper above the standard python dictionary. In the code above, I created a new item that stores five fields from the website. As you can see, I am parsing the Projects grid from the Freelancer.com website.
The Spider implementation:
from scrapy import Spider
from wsfreelancer.items import WsfreelancerItem
class FreelancerSpider(Spider):
name = "freelancer"
allowed_domains = ["freelancer.com"]
start_urls = (
'http://www.freelancer.com/jobs/1',
'http://www.freelancer.com/jobs/2'
)
def parse(self, response):
for selector in response.xpath('//*[@id="project_table_static"]/tbody/tr'):
frItem = WsfreelancerItem()
frItem['project_name'] = selector.xpath('td[1]/text()').extract()
frItem['nr_of_bids'] = selector.xpath('td[3]/text()').extract()
frItem['description'] = selector.xpath('td[2]/text()').extract()
frItem['skills'] = selector.xpath('td[4]/a/text()').extract()
frItem['price'] = selector.xpath('td[7]/text()').extract()
yield frItemThe FreelancerSpider derives from the Spider class, and has to have a name (you can use this name when starting scraping from the command line). The allowed_domains and start_urls go hand in hand and their names are self-explanatory. As you can see, Scrapy supports XPath and CSS for querying HTML elements and data.
The parse method is automatically invoked. I create a selector for the HTML table (with id project_table_static) rows (these contain the data that I am interested in), then I extend the xpath to access the table cells and extract the text from these. I create a new item for each row in the table and return the item using the yield keyword (last line of the for statement).
You can use the Copy XPath functionality from Chrome Developer Tools to figure out the exact path for the data that you want to extract, but if you're using Firefox, then FireBug has the same feature. Select the HTML element in the Elements view and right click on the data you want to extract and select Copy XPath from the opening menu (you also have Copy CSS path).
You can run the scraper using the command:
$> scrapy crawl freelancerYou can export the crawled data to json or csv using:
$> scrapy crawl freelancer -o items.csvA sample output from the csv file: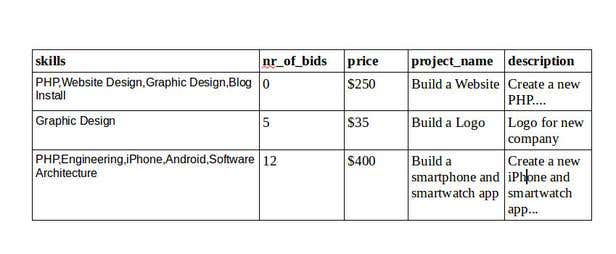
As you can see, building a Web scraper using Scrapy and a browsers' developer tools is not so hard. With this tool, you can gather a lot of useful data from the Internet with little effort. Scrapy has more functionality than I presented so if you have other specific scenarios in mind, please consult the documentation.